
序列化与反序列化
0x1 什么是反序列化
序列化:对象 -> 字符串
反序列化:字符串 -> 对象
0x2 为什么要反序列化
- 传递数据,将对象序列化成一段流,用于传输
- 用于进程之间的通讯
0x3 序列化的优点
- 数据持久化 ,可以将对象的数据永久存储在硬盘中,即将对象序列化成文件
- 实现远程通信,在网络上传输对象(传输的是对象的字节流)
0x4 序列化场景
- 将对象持久化保存在硬盘中,即序列化到文件或数据库中
- 网络中使用套接字socket传输对象
- 通过RMI协议传输对象
0x5 序列化和反序列化协议
- XML SOAP
- JSON
- Protobuf
Serializable 接口
Serializable的基本使用
序列化类的属性没有实现 Serializable 那么在序列化就会报错
只有实现 了Serializable 或者 Externalizable 接口的类的对象才能被序列化为字节序列。(不是则会抛出异常)
Serializable 接口是 Java 提供的序列化接口,它是一个空接口,所以其实我们不需要实现什么。
1 | package Serialize; |

如果去掉这个接口则会报错

Serializable特点1: 父类没实现Serializable接口,子类实现了,那么子类也是可以被序列化的
见特点2
Serializable特点2:为继承接口的父类调用无参构造器
1 | package Serialize; |
简单讲解一下这串代码,定义了两个类Person,Student,学生类继承的Person并且使用了Serializable接口,而父类Person则没有使用Serializable接口。则Student类可以序列化,而Person则不能反序列化。
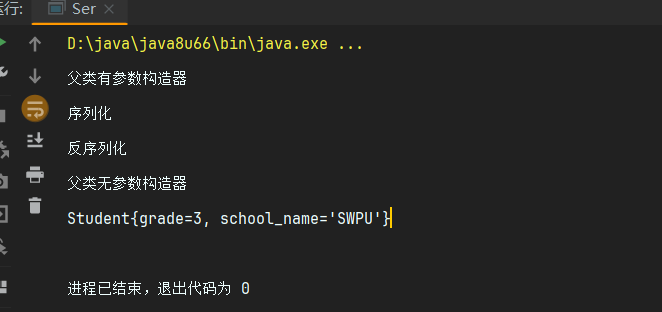
这是输出结果,可以看到我们反序列化一个Student对象,其中四个属性均有值,但是反序列化出来的结果则只有年级和学校,说明Person类没有成功序列化出来(因为没有使用Serializable接口),并且反序列化的时候调用了Person类的无参数构造函数
这是他的一个特性:
父类如果没有实现序列化接口,那么将需要提供无参构造函数来重新创建对象
目的:重新初始化父类的属性,例如 Person 因为没有实现序列化接口,因此对应的 age和name 属性就不会被序列化,所以需要调用无参构造器将属性设置为null
Serializable特点3: 静态static成员变量是不能被序列化
static是在类加载的时候就定义的,是类的变量而不是对象的属性,所以不会被序列化
例如
1 | package Serialize; |
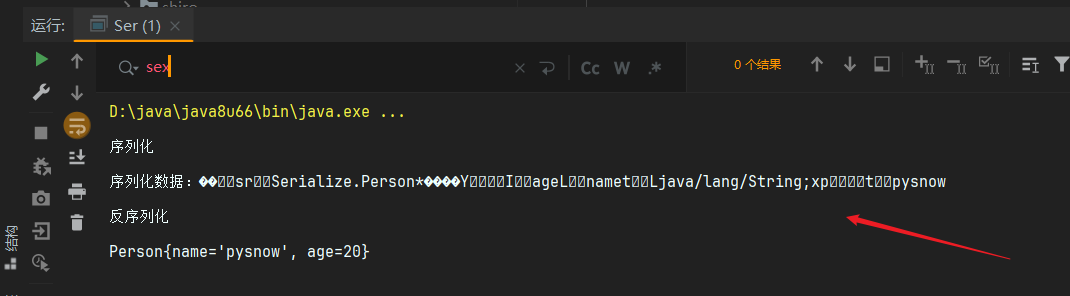
可以看到序列化后的数据里面没有sex这个字段
Serializable特点4:transient 标识的对象成员变量不参与序列化
1 | package Serialize; |
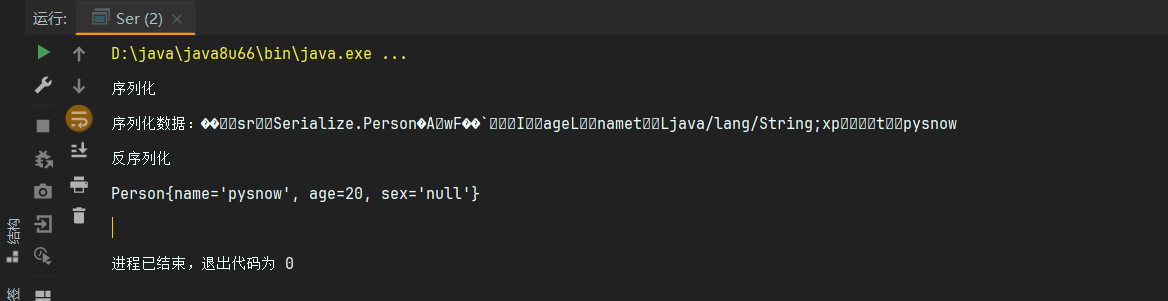
简单来讲就是被transient标记的成员属性不参与序列化,但是还是作为一个正常的成员属性处理,跟static不同的是他是对象里面的而不是在类里面的变量,只不过transient标记的变量不能够存储下来
序列化ID
1 | private static final long serialVersionUID = 1L; |
序列化ID作用
我们知道如果我们要反序列化一个对象,那么客户端上就必须有一个对应的类。
比如说这里
1 | class Person implements Serializable { |
我们反序列化一个Person对象,但是我们对这个序列化的字节流做点修改,把int age改为String age,这样的情况下还能反序列化成功吗,很明显是不行的,因为这都不是一个类了,而JVM用来区分这个序列化字节流所表示的对象是不是对应客户端的某个类就用到了SerialVersionUID。
你可以理解为这是类class的一个private static final long属性,他默认是通过JVM根据class文件计算得到的,而由该class生成的序列化字节流的SerialVersionUID则跟该class文件计算的UID结果一样,而如果我们擅自修改了序列化字节流中某个成员属性的类型则会导致SerialVersionUID变化,在反序列化的时候就会不匹配SerialVersionUID
梳理一下
- SerialVersionUID是用来区别类唯一性的UID标识
- SerialVersionUID可以在类定义的时候通过private static final long serialVersionUID = 1L;进行修改
- 如果为指定serialVersionUID属性,则有JVM自行计算
- 不同JVM计算的SerialVersionUID不同,所以同一个序列化字节流在不同的JVM虚拟机中反序列化可能失败
影响序列化ID的因素
- 手动去修改导致当前的 serialVersionUID 与序列化前的不一样。
- 未设置 serialVersionUID 常量,则JVM 内部会根据类结构去计算serialVersionUID ,在类结构发生改变时serialVersionUID 发生变化。
- 反序列和序列化操作的虚拟机不一样可能导致计算出来的 serialVersionUID 不一样
- 类的方法 ,static变量和使用transient 修饰的实例变量 ,增加或删除实例变量 均不影响serialVersionUID
Externalizable接口
1 | public interface Externalizable extends java.io.Serializable { |
Externalizable接口继承了Serializable接口并定义了writeExternal和readExternal方法
也就是说Externalizable 将序列化和反序列化的工作完全交给了程序员,序列化和反序列化的逻辑全部由程序员编写,这样做的好处是程序员可以优化算法提升效率
Java 的序列化步骤与数据结构分析
writeObject
ObjectOutputStream构造函数
首先我们看一下这个类的构造函数,理解一下各个成员属性的含义方便后续代码的理解
1 | public ObjectOutputStream(OutputStream out) throws IOException { |
1 | protected void writeStreamHeader() throws IOException { |

第一个是 序列化协议 ,第二个是 序列化协议版本
writeObject
首先是序列化的数据,则这我将使用一个继承类方便观看writeObject对于父类的数据怎么处理的
1 | package Serialize; |
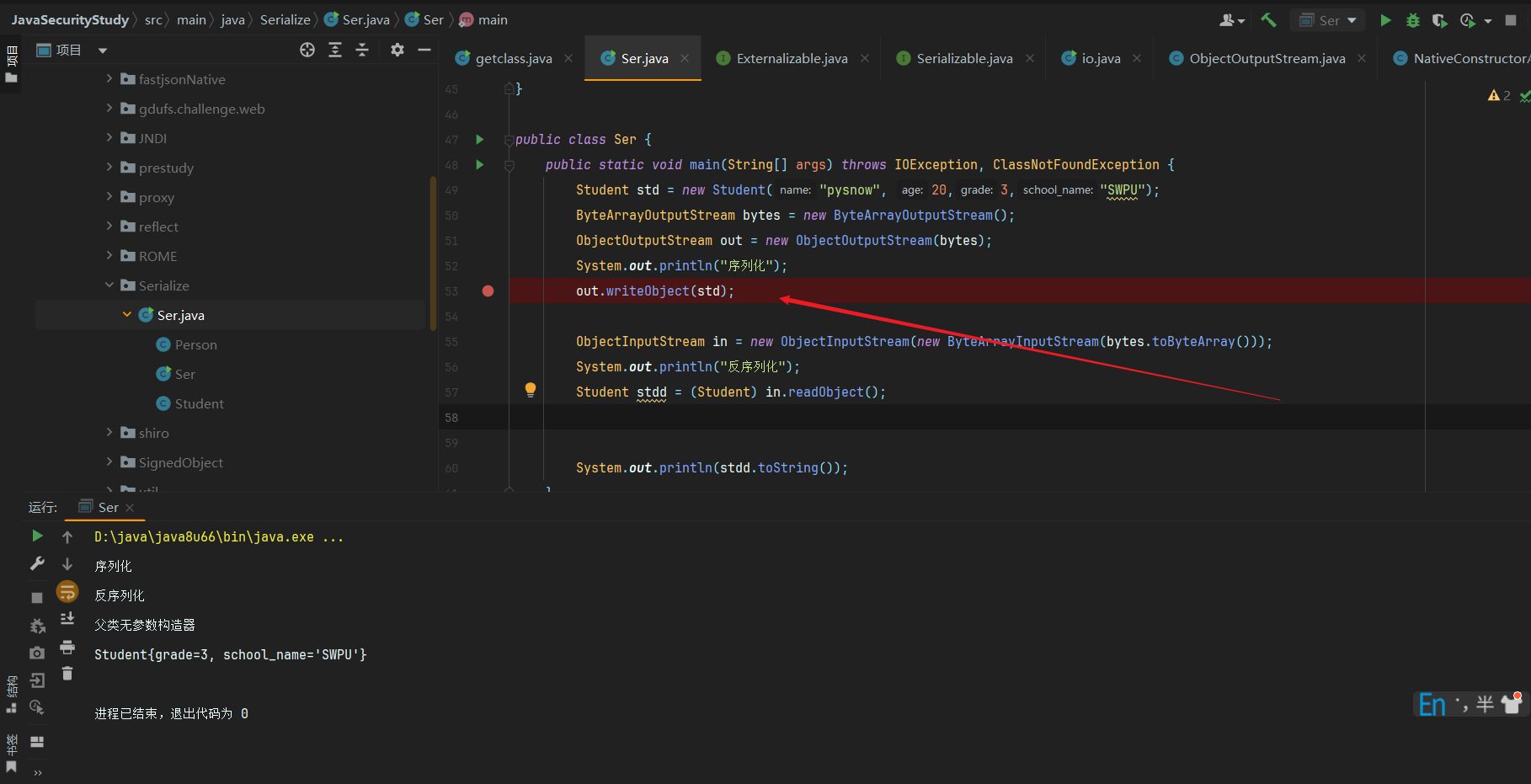
ObjectOutputStream->writeObject
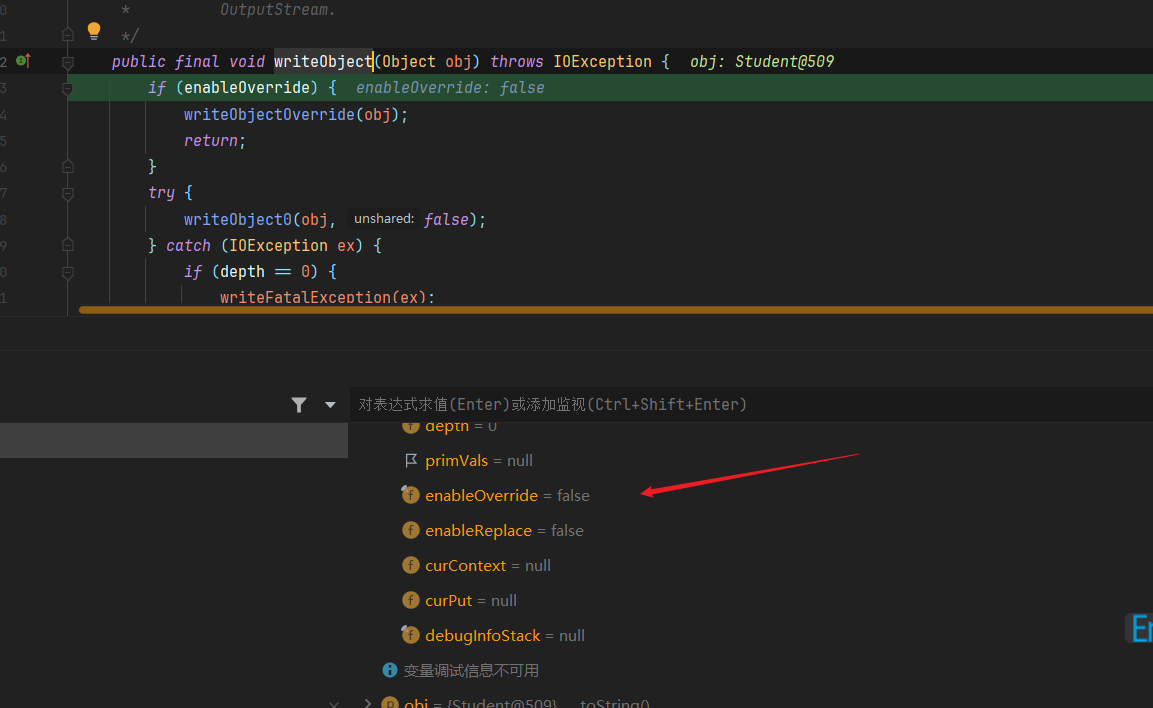
首先判断 enableOverride 是否为true,这里为false则进入 writeObject0 方法
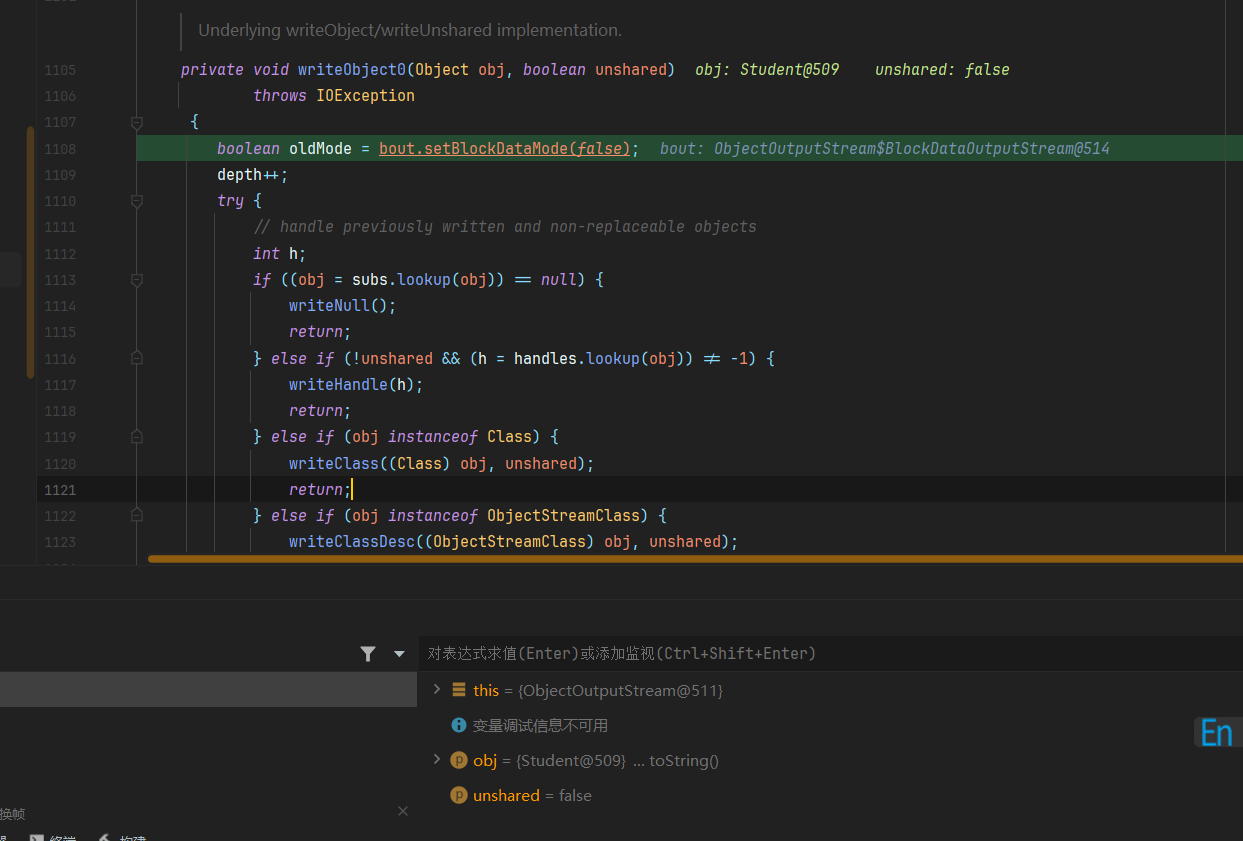
1 | private void writeObject0(Object obj, boolean unshared) |
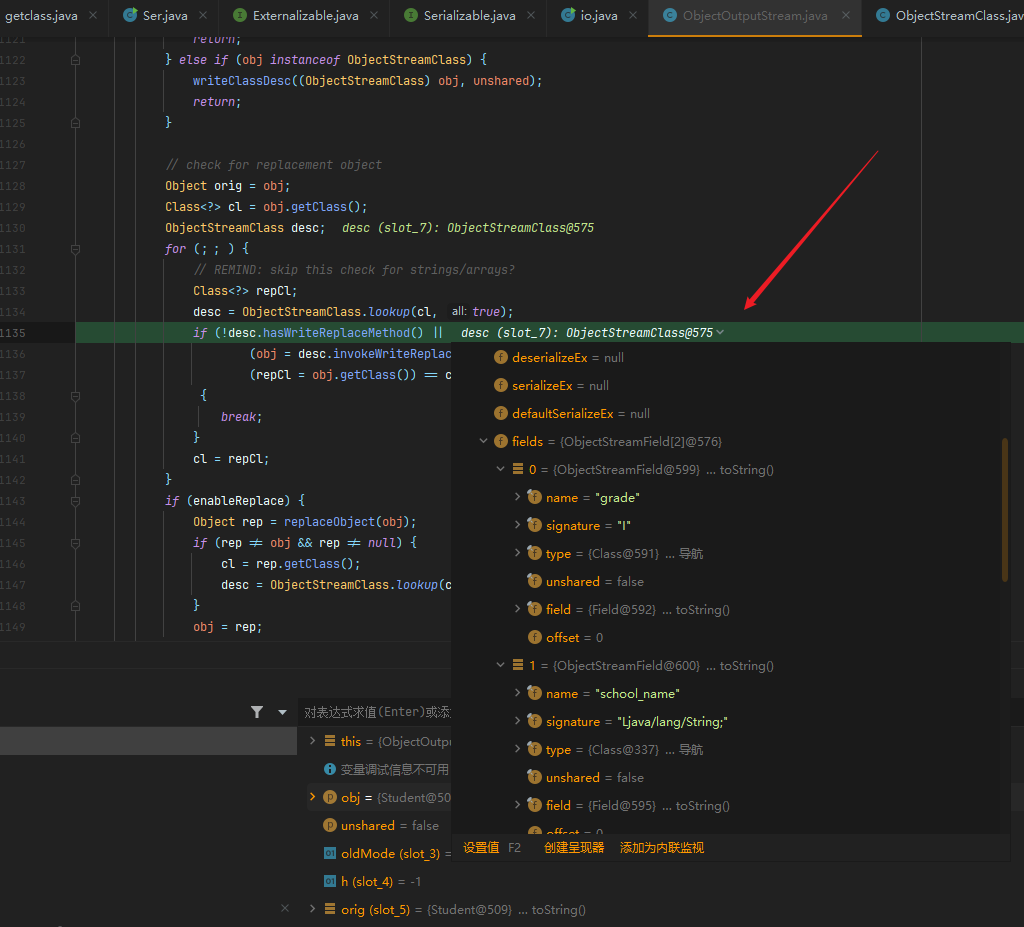
1 | desc = ObjectStreamClass.lookup(cl, true); |
首先使用ObjectStreamClass.lookup方法传入当前对象的class对象作为参数
我们看下这个lookup方法
1 | static ObjectStreamClass lookup(Class<?> cl, boolean all) { |
这个lookup可以获取序列化对象的属性信息以及其父类的属性值,至于父类的代码逻辑则在构造函数那
1 | private ObjectStreamClass(final Class<?> cl) { |
通过lookup父类的class对象获取父类的属性信息
可以看到这个构造函数使用了大量的。
接着回到writeObject0函数
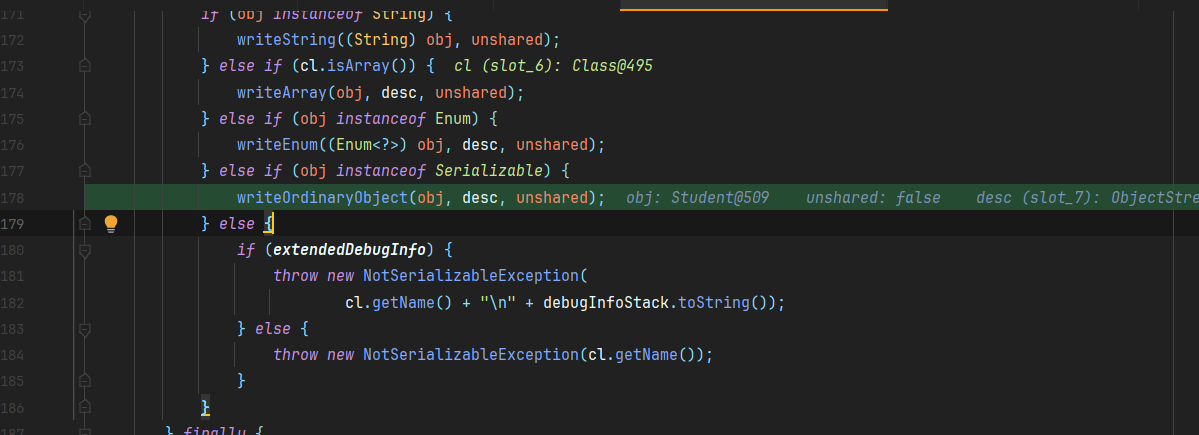
当对象继承了Serializable接口则调用writeOrdinaryObject,否则抛出NotSerializableException异常
1 | private void writeOrdinaryObject(Object obj, |
很明显到这里就是序列化写数据的逻辑了
1 | bout.writeByte(TC_OBJECT); |

写入ClassDesc之前
1 | [120, 112, 0, 17, 83, 101, 114, 105, 97, 108, 105, 122, 101, 46, 83, 116, 117, 100, 101, 110, 116, -110, 108, 77, -35, 41, 26, 23, -111, 2, 0, 2, 73, 0, 5, 103, 114, 97, 100, 101, 76, 0, 11, 115, 99, 104, 111, 111, 108, 95, 110, 97, 109, 101, 116, 0, 18, 76, 106, 97, 118, 97, 47, 108, 97, 110, 103, 47, 83, 116, 114, 105, 110, 103, 59, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 其他 924 个] |
写入之后
接着最后进入writeSerialData,如果没有继承Externalizable接口的话
1 | private void writeSerialData(Object obj, ObjectStreamClass desc) |
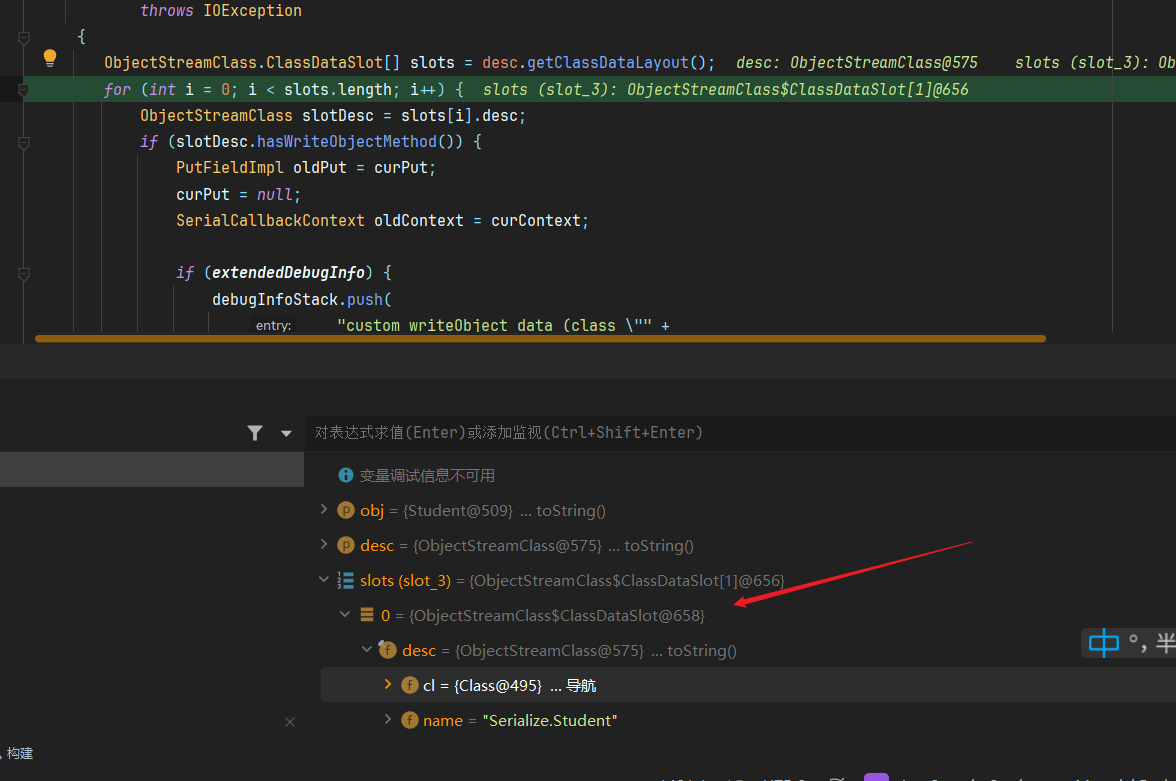
这里可以看到desc.getClassDataLayout()获取的DataLayout就是将 ObjectStreamClass 封装了一下
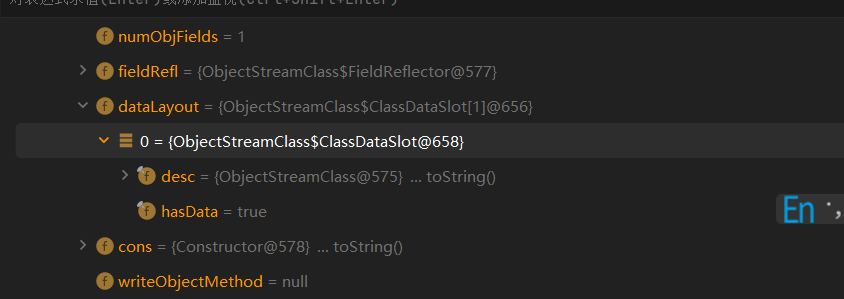
接着遍历这个DataLayout数组,获取里面的desc,也就是获取序列化对象的描述
这里数组只有一个是因为Person这个父类没有继承Serializable接口
接着判断是否有writeObject这个自定义私有方法,如果有则调用我们自己定义的writeObject,否则则进入defaultWriteFields(obj, slotDesc)。
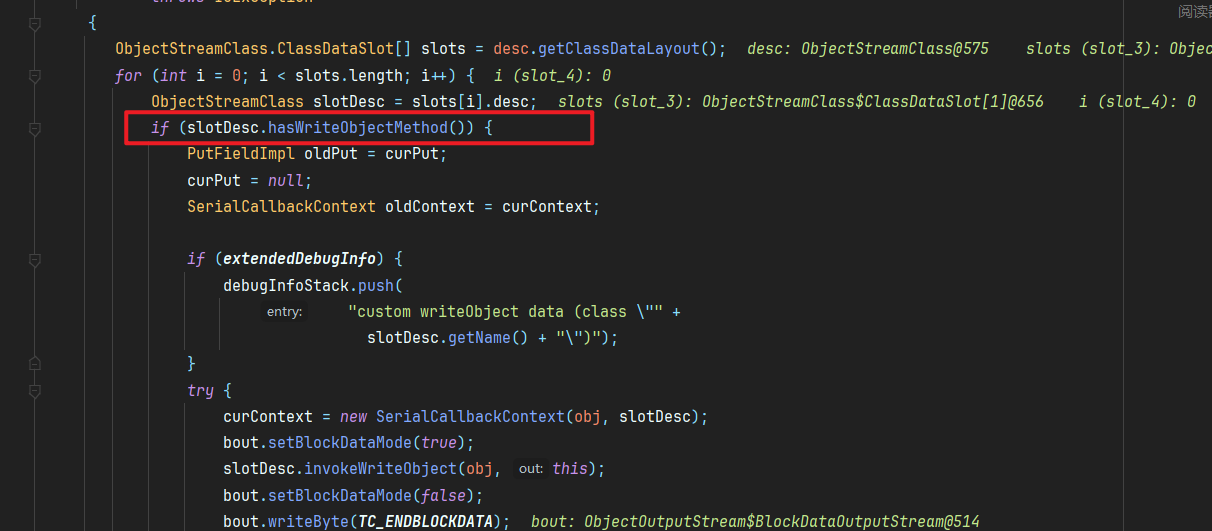

1 | private void defaultWriteFields(Object obj, ObjectStreamClass desc) |
这个defaultWriteFields则是写入对象数据的逻辑了
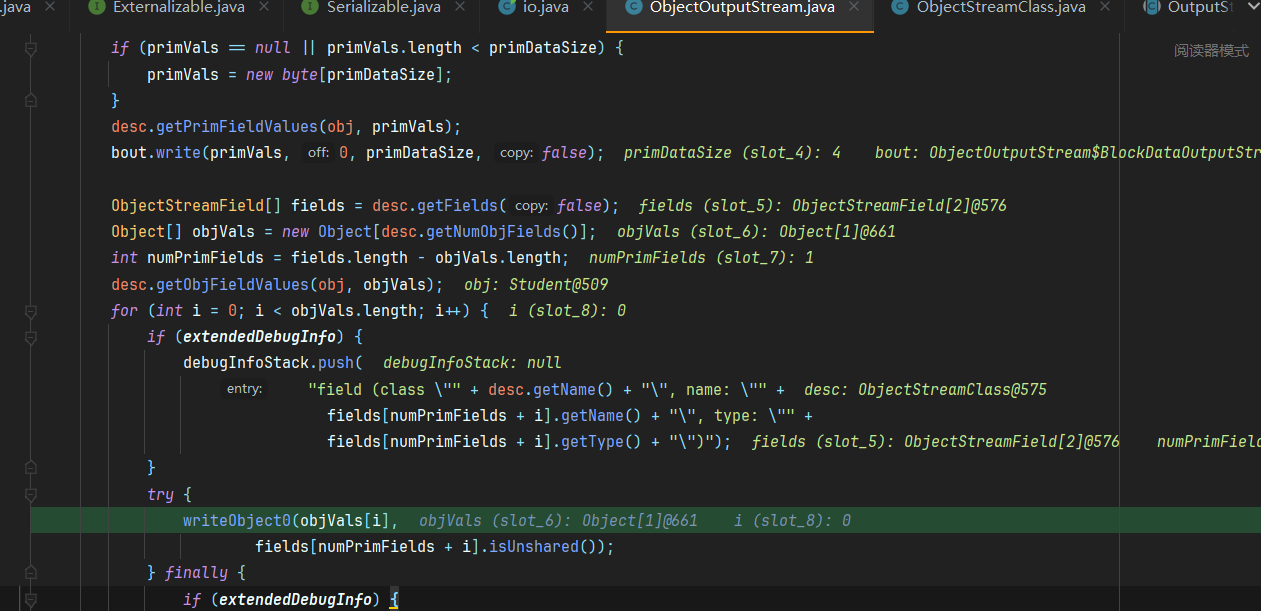
这里的大致过程可以理解为,先给当前序列化对象的基本数据类型赋值,比如说String,int等属性,接着对那些引用属性再进行writeObject0操作,对对象成员属性进行序列化,这是一个递归的过程
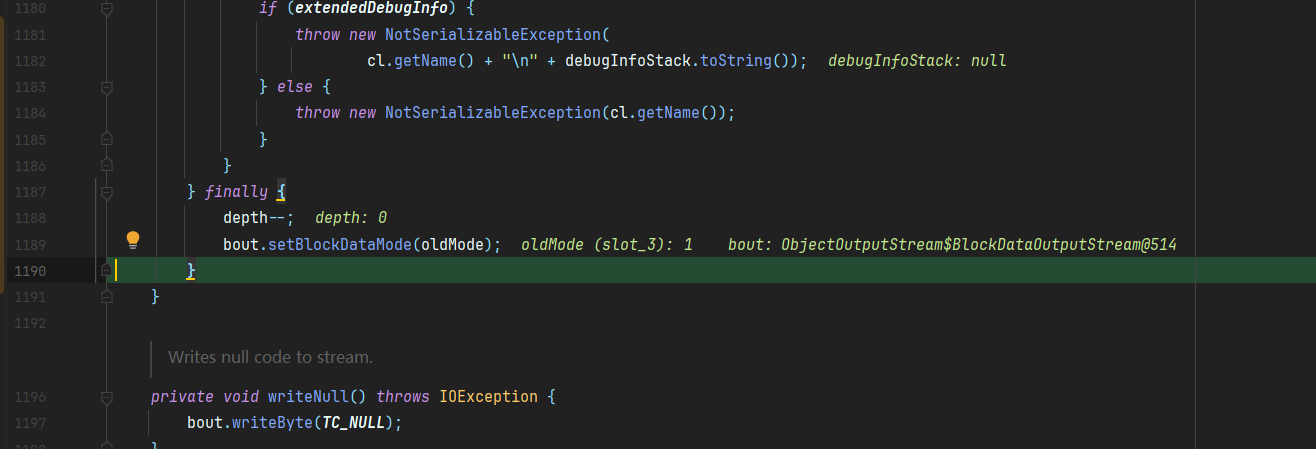
最后知道递归深度减少为0之后闭合序列化字节流,退出
readObject
1 | public final Object readObject() |
同样的也是调用readObject0
1 | private Object readObject0(boolean unshared) throws IOException { |
运行到判断对象所对应的类型为TC_OBJECT,则调用readOrdinaryObject读取对象信息

readOrdinaryObject
1 | private Object readOrdinaryObject(boolean unshared) |
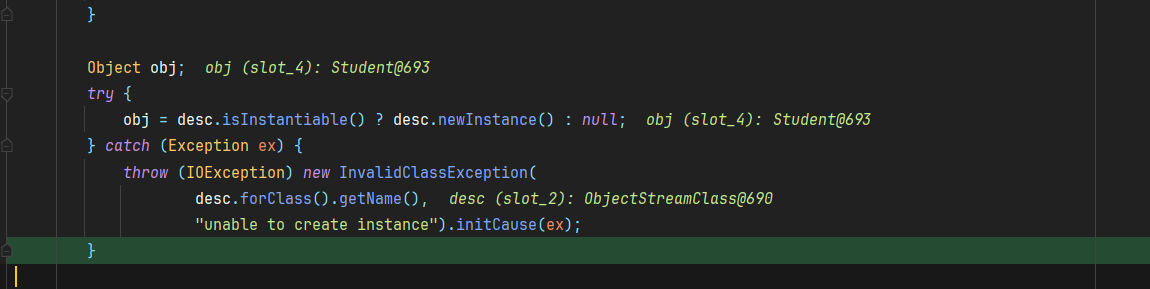
首先实例化了一个指定的反序列化对象Student,目前还没有设置值

接着还是一样的判断是否继承Externalizable接口,如果是则执行用户自己定义的对象反序列化逻辑,否则则使用默认的反序列化逻辑,即字节流将中对象数据部分读取成对象
readSerialData
1 | private void readSerialData(Object obj, ObjectStreamClass desc) |
前面逻辑还是跟writeSerialData一样,获取desc的Data数组,遍历
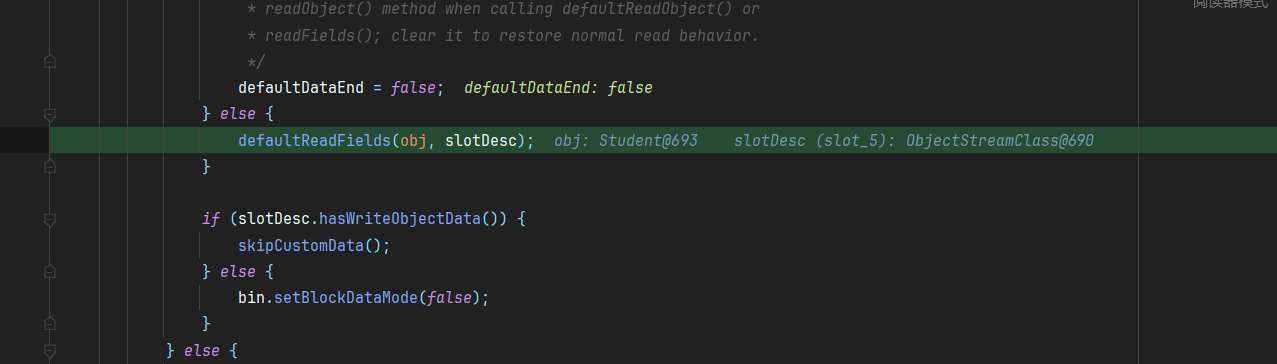
直到执行到defaultReadFields这里,读取字节流中的对象属性值
后面的代码代码逻辑就跟WriteObject很像了
学完这些就有利于我们后面分析java序列化字节流的结构